
用有言,
创作你的3D数字人AI视频
一、什么是“形象克隆”和“音色克隆”——把“你”搬进数字世界
形象克隆:把你的五官、面部细节和风格转成可编辑的超写实3D数字人。只要上传少量照片(参考操作为 5 张),几分钟内即可生成可换装、可调妆容、能做表情包和出镜的视频分身。
音色克隆:把你的声音“克隆”成可在 TTS 中调用的音色。录制一段示例朗读(通常 10–20 秒即可),系统便可生成高度还原你语气、节奏与情感色彩的语音素材,随时用于视频配音或客服语音。
这对个人创作者、企业品牌与机构培训都有直接价值:零演员成本、零档期冲突、同一口径跨平台复用。
二、为什么要做人物与声音克隆
- 节省成本与时间:彻底摆脱演播室、外包配音或约拍时间,单人就能产出专业级内容。
- 保持人格化与一致性:品牌代言、专家解读或员工培训可用同一“人设”与声音口径,保持传播一致性。
- 提高转化与信任:观众更信任“熟悉的面孔与声音”,带货、教育与客服场景的接受度和完播率显著上升。
- 多场景快速迭代:节假日、活动或市场突发事件时,可在分钟级生成新视频并发布,抢占传播窗口。
三、如何在有言实现人物和声音克隆?
快速生成:几分钟出分身、实时试听音色
- 形象克隆用高精度人脸建模与自动化贴图流程,上传 5 张合规照片后在 Lab 实验室点击生成,数分钟即可得到初版 3D 分身;
- 音色克隆采用成熟的 TTS + 语音克隆流程,录音样本提交后短时间内生成可调用的专属音色。
可编辑与可复用:换装、微调与资产库
生成后,你可以换装、改发型、微调五官比例或妆容,保存为品牌/个人的“数字资产包”,在不同视频中反复调用。
高拟真与场景化:表情、口型与情绪同步
系统不仅生成静态形象,还支持表情包预览、口型同步与语义驱动的情绪调节,呈现接近真人的表达效果。
四、魔珐有言核心优势
- 低门槛:无需美术或音频专业背景,普通用户也能操作;
- 速度快:从照片/录音到可用素材,分钟到小时级完成;
- 风格化:既能高度还原个人特征,也支持打造多个人设(职场、古风、赛博等);
- 可扩展:支持导出音频、视频或接入后端 API,用于大屏、直播或客服系统;
- 隐私与可控:用户可管理自己的分身与音色资产、设置使用权限(注意合规与授权流程,见下节)。
五、操作指南
形象克隆快速流程(长尾关键词:如何生成3D数字分身)
- 打开有言 Lab 实验室 → 申请内测或输入邀请码进入体验区;
- 按拍摄小贴士准备 5 张清晰头像照(正面、两侧、上下角度为佳);
- 上传照片、选择性别/族裔偏好 → 点击生成,等待几分钟;
- 进入编辑面板换装/调妆,预览表情包与出镜效果 → 保存并导出至项目库。
拍照小贴士:光线均匀、无遮挡、面部表情自然、不要美颜滤镜,手机原图优先。

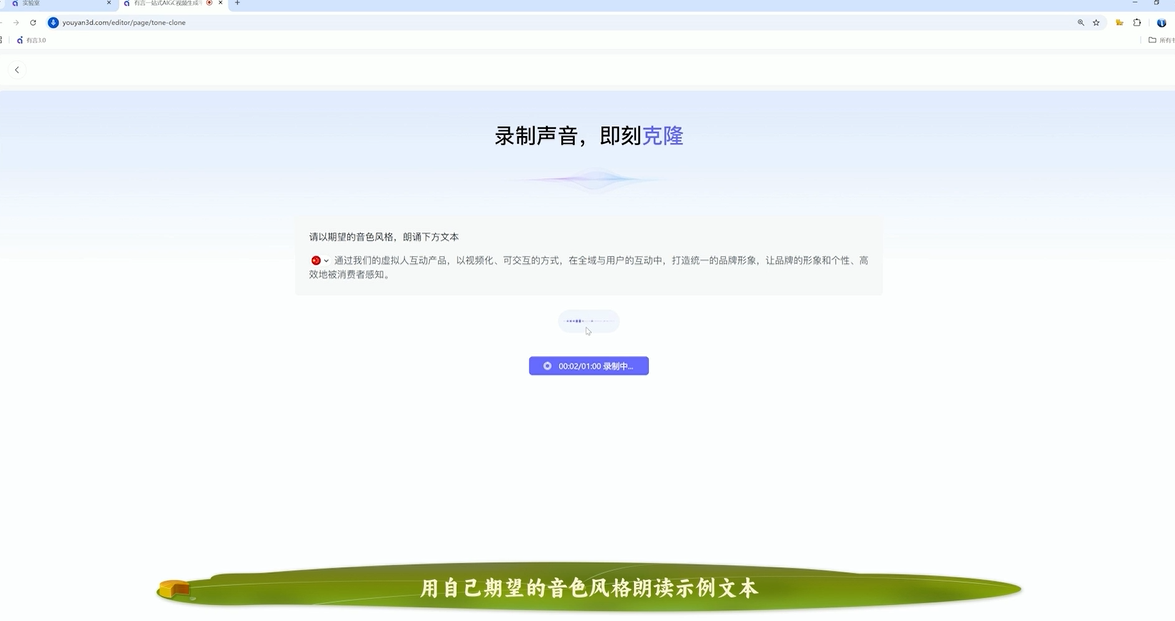
音色克隆快速流程(长尾关键词:音色克隆操作步骤)
- 在 Lab 点击「音色克隆」→ 录制 10–20 秒的示例朗读(选示例文本以体现常用语气);
- 提交并试听,若满意点击开始克隆;
- 克隆完成后在「我的音色」中调用 TTS 输出,或与 3D 分身同步生成视频配音。
录音小贴士:安静环境、接近麦克风 10–15 cm、用平常说话的语速与情绪进行录制。
shuziren1


